# Web 音视频(四)在浏览器中处理音频
为什么单独介绍?
- 网络上缺乏音频处理的资料,绝大多数示例都是针对视频而略过音频,很多人在网上寻找音频处理的示例
- 对前端开发者来说,音频处理相对视频略微复杂一些
所以,本文专门针对音频数据,汇总讲解采集-处理-编码-封装全过程,帮助初学者入门。
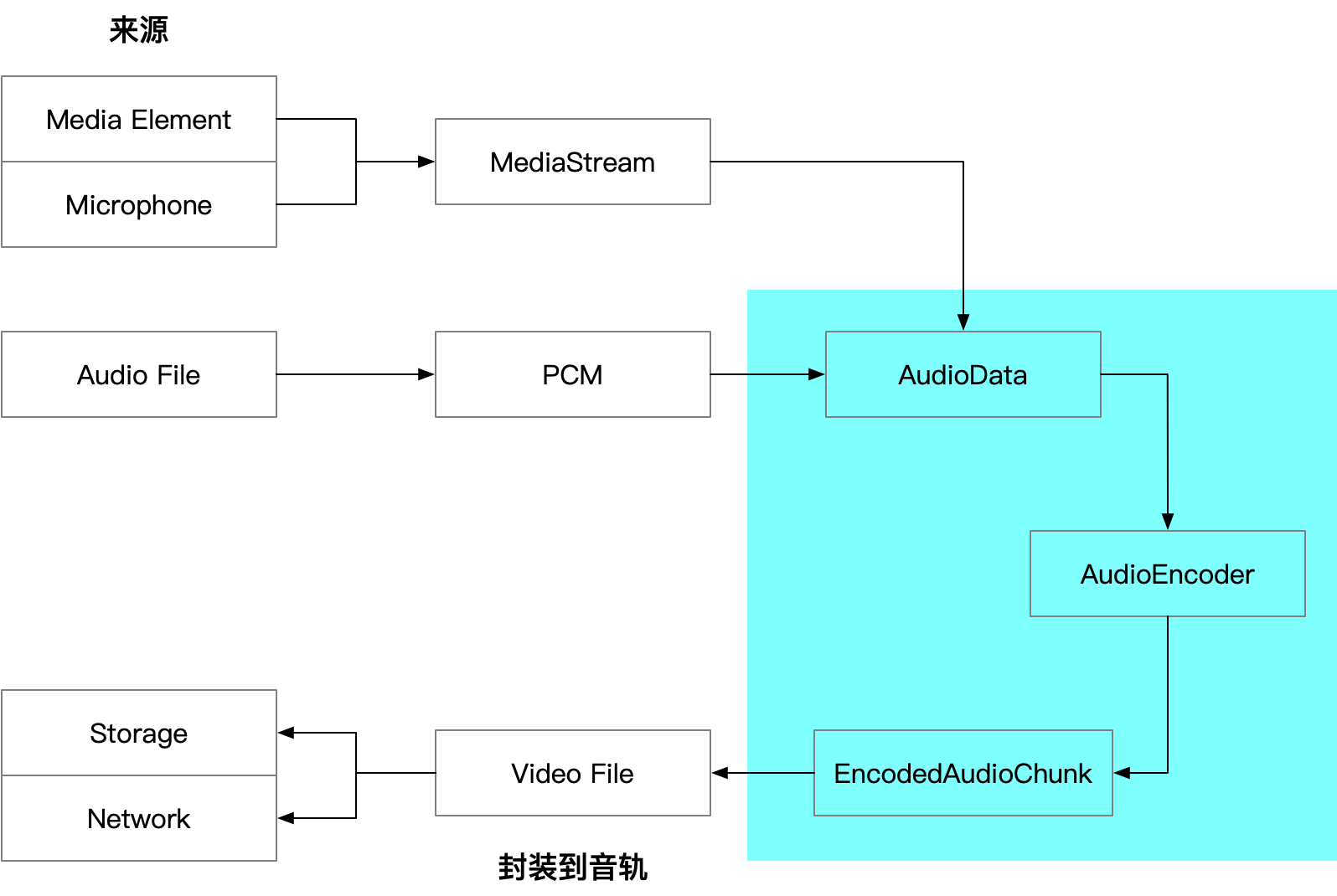
上图是在 Web 中从采集音频到封装文件的大致流程。
你可以跳过原理介绍,直接查看 WebAV 编码封装音频示例
# 采集
# 数字化声波
声音的本质是波,对一段连续声波进行采样,每一个点用一个浮点数来表示,声音就被数字化成了一个浮点数组;js 中常使用 Float32Array 来记录数字化后的浮点数组。
注:具体是那个 ArrayBuffer 的子类型取决于浏览器,后文使用 Float32Array 指代 PCM 对应的数据
如果对音频、波、数字化没什么概念,强烈建议体验 Waveforms (opens new window)
数字化(Pulse Code Modulation, PCM)一段声音后(Float32Array),还需要几个必要属性来描述这段数据
- SampleRate(采样率):采样声波的频率,48KHz 就是每秒采样 48000 个数字
- ChannelCount(声道数):声音来源数量,比如两个声波(双声道)采样后会得到两个
Float32Array,通常会将它们前后拼接成一个Float32Array,前一半为左声道声波采样数据,后一半为右声道数据
*为什么没有时长属性?*
因为时长可以通过 ChannelCount、SampleRate 算出来
duration = Float32Array.length / ChannelCount / SampleRate
假设一段单声道音频数据(Float32Array)长度为 96000,SampleRate 为 48KHz
那么这段音频的持续时长为: 96000 / 1 / 48000 = 2 秒
# 声音数据(Float32Array)来源
列举三个主要音频来源,转换到 Float32Array 的过程
- 本地或网络音频文件 ->
ArrayBuffer->AudioContext.decodeAudioData->Float32Array Video or Audio Element->MediaElement.captureStream()->MediaStream->MediaStreamTrack->MediaStreamTrackProcessor->AudioData->Float32Array- 麦克风、屏幕分享 ->
MediaStream-> ...(如上)
转换过程不算复杂,只是需要阅读的 API 比较多;获得 Float32Array 后就可以进行下一步处理。
# 处理
图像处理的计算复杂度高很多,依赖硬件加速;对前端开发者来说是绘制到 canvas,使用对应的 API 去操作即可,反而对音频处理更陌生。
这里举几个常见例子,帮助大家熟悉音频处理逻辑;可以选择写代码编辑音频数据,也可以借助已有的 Web Audio API (如 重采样)。
# Web Audio API
Web Audio API 提供了在 Web 上控制音频的一个非常有效通用的系统,允许开发者来自选音频源,对音频添加特效,使音频可视化,添加空间效果(如平移)等等。
先提一下 Web Audio API (opens new window),它包含非常多的 API 用于在 Web 中创建、处理音频;
本文会依赖其中少量 API,但不会过多介绍,有兴趣的同学可以阅读张鑫旭的文章 JS 交互增加声音 (opens new window)
# 音量调节
中学物理学过,声波的振幅表示音量大小,乘以一个数可以改变振幅(音量);
所以 Float32Array 乘以 0~1 之间小数相当于降低音量,大于 1 相当于增大音量
for (let i = 0; i < float32Arr.length; i++) float32Arr[i] *= 0.5;
以上是原理,但人耳对音量大小的感知是对数而不是线性关系,实际音量调节要复杂很多,可阅读 PCM 音量控制 (opens new window)
# 混流
因为声音的本质是波,所以多个声音混合即波的叠加,使用加法即可
float32Arr1 + float32Arr2 => outFloat32Arr
const len = Math.max(float32Arr1.length, float32Arr2.length);
const outFloat32Arr = new Float32Array(len);
for (let i = 0; i < len; i++)
outFloat32Arr[i] = (float32Arr1[i] ?? 0) + (float32Arr2[i] ?? 0);
# 声音淡入/淡出
最常见的场景,点击按钮暂停音乐时,声音大小是快速降低为 0,而不是瞬间消失。
多年前很多音乐播放器是没有做声音淡出的,现在已经体验不到那种声音瞬间消失的难受感觉了。
假设需要截断一个音频,为了前半段的音频结尾听起不那么难受,需要将结尾的 0.5s 音量降低至 0;音频采样率为 48KHz。
// 生成 1s 随机 PCM 数据
const pcmF32Arr = new Float32Array(
Array(48000)
.fill(0)
.map(() => Math.random() * 2 - 1)
);
// 开始位置距离结尾 0.5s(采样率 / 2)
const start = pcmF32Arr.length - 1 - 48000 / 2;
for (let i = 0; i < 48000 / 2; i += 1)
// 逐渐降低音量
pcmF32Arr[start + i] *= 1 - i / 48000 / 2;
# 重采样
当输入的音频采样率跟输出不一致,或需要混流两个采样率不同的音频时,就需要对音频进行重采样,改变音频的采样率。
重采样的原理是对 Float32Array 进行抽取或插值;
比如,48KHz 采样率的音频 1s 有 48000 个点(数字),采样率降低至 44.1KHz 则 1s 的音频需要丢掉其中 48000 - 44100 个点。
在 Web 中 AudioContext、OfflineAudioContext API 已经提供重采样能力,我们可以利用 API 来对音频进行重采样,无需自己实现相关算法。
使用 OfflineAudioContext 重采样音频数据
/**
* 音频 PCM 重采样
* @param pcmData PCM
* @param curRate 当前采样率
* @param target { rate: 目标采样率, chanCount: 目标声道数 }
* @returns PCM
*/
export async function audioResample (
pcmData: Float32Array[],
curRate: number,
target: {
rate: number
chanCount: number
}
): Promise<Float32Array[]> {
const chanCnt = pcmData.length
const emptyPCM = Array(target.chanCount)
.fill(0)
.map(() => new Float32Array(0))
if (chanCnt === 0) return emptyPCM
const len = Math.max(...pcmData.map(c => c.length))
if (len === 0) return emptyPCM
const ctx = new OfflineAudioContext(
target.chanCount,
(len * target.rate) / curRate,
target.rate
)
const abSource = ctx.createBufferSource()
const ab = ctx.createBuffer(chanCnt, len, curRate)
pcmData.forEach((d, idx) => ab.copyToChannel(d, idx))
abSource.buffer = ab
abSource.connect(ctx.destination)
abSource.start()
return extractPCM4AudioBuffer(await ctx.startRendering())
}
WebAV 中的 audioResample 函数源码 (opens new window)
TIP
WebWorker 环境中不存在 OfflineAudioContext,可采用 js 实现的音频重采样库来实现,如 wave-resampler (opens new window)
import { resample } from 'wave-resampler';
// The Worker scope does not have access to OfflineAudioContext
if (globalThis.OfflineAudioContext == null) {
return pcmData.map(
(p) =>
new Float32Array(
resample(p, curRate, target.rate, { method: 'sinc', LPF: false })
)
);
}
# 编码音频
因为 AudioEncoder (opens new window) 只能编码 AudioData (opens new window) 对象,所以需要先将 Float32Array 转换成 AudioData 对象。
new AudioData({
// 当前音频片段的时间偏移
timestamp: 0,
// 双声道
numberOfChannels: 2,
// 帧数,就是多少个数据点,因为双声道,前一半左声道后一半右声道,所以帧数需要除以 2
numberOfFrames: pcmF32Arr.length / 2,
// 48KHz 采样率
sampleRate: 48000,
// 通常 32位 左右声道并排的意思,更多 format 看 AudioData 文档
format: 'f32-planar',
data: pcmF32Arr,
});
创建并初始化音频编码器
const encoder = new AudioEncoder({
output: (chunk) => {
// 编码(压缩)输出的 EncodedAudioChunk
},
error: console.error,
});
encoder.configure({
// AAC 编码格式
codec: 'mp4a.40.2',
sampleRate: 48000,
numberOfChannels: 2,
});
// 编码原始数据对应的 AudioData
encoder.encode(audioData);
TIP
创建编码器之前,记得先使用 AudioEncoder.isConfigSupported 检测兼容性
# 封装
继续使用 mp4box.js 来演示封装 EncodedAudioChunk
主要代码
const file = mp4box.createFile();
const audioTrackId = file.addTrack({
timescale: 1e6,
samplerate: 48000,
channel_count: 2,
hdlr: 'soun',
// mp4a是封装格式,对应的 AAC 是编码格式
type: 'mp4a',
// meta 来原于 AudioEncoder output 的参数
// 不传递这个字段,windows media player 播放视频时没有声音
description: createESDSBox(meta.decoderConfig.description),
});
/**
* EncodedAudioChunk | EncodedVideoChunk 转换为 MP4 addSample 需要的参数
*/
function chunk2MP4SampleOpts(
chunk: EncodedAudioChunk | EncodedVideoChunk
): SampleOpts & {
data: ArrayBuffer,
} {
const buf = new ArrayBuffer(chunk.byteLength);
chunk.copyTo(buf);
const dts = chunk.timestamp;
return {
duration: chunk.duration ?? 0,
dts,
cts: dts,
is_sync: chunk.type === 'key',
data: buf,
};
}
// AudioEncoder output chunk
const audioSample = chunk2MP4SampleOpts(chunk);
file.addSample(audioTrackId, audioSample.data, audioSample);
限于篇幅,上述代码依赖的 createESDSBox 的源码 (opens new window)在这里
如果你需要自己写代码实现音频封装逻辑,需要注意:
- mp4box.js 创建 ESDS Box 还有 Bug 未修复,查看详情 (opens new window)
- 音频轨道与视频轨道创建完成(addTrack)之后才能添加数据(addSample),而创建轨道都是需要等待编码器(VideoEncoder、AudioEncoder)的 meta 数据,请查看同步创建音视频轨道 (opens new window)代码
- 封装的音频数据时间(
Sample.cts)似乎不能用来控制音频偏移,如果某一段时间没有声音,你仍然需要填充数据,比如 10s 没有声音的 PCM 数据
new Float32Array(Array(10 * 48000).fill(0))
# WebAV 编码封装音频示例
如果从零开始实现编码封装音频,除了参考以上的原理介绍,还需要阅读大量 API 和细节处理。
你可以略过细节,使用 @webav/av-cliper 提供的工具函数 recodemux 、 file2stream 来快速编码封装音频,创建视频文件。
以下是从麦克风获取音频数据并编码封装的核心代码。
import { recodemux, file2stream } from '@webav/av-cliper';
const muxer = recodemux({
// 目前视频是必填的,参考上一篇文章获取视频帧
video: {
width: 1280,
height: 720,
expectFPS: 30,
},
audio: {
codec: 'aac',
sampleRate: 48000,
channelCount: 2,
},
});
// 500ms 写一次文件
// upload or write stream
const { stream, stop: stopOutput } = file2stream(muxer.mp4file, 500);
const mediaStream = await navigator.mediaDevices.getUserMedia({
video: true,
audio: true,
});
const audioTrack = mediaStream.getAudioTracks()[0];
const reader = new MediaStreamTrackProcessor({
track: audioTrack,
}).readable.getReader();
async function readAudioData() {
while (true) {
const { value, done } = await reader.read();
if (done) {
stopOutput();
}
await muxer.encodeAudio(value);
}
}
readAudioData.catch(console.error);
这里是从摄像头、麦克风录制数据导出 MP4 文件的完整示例 (opens new window)代码,点击立即体验 DEMO (opens new window)
# 附录
- WebAV (opens new window) 基于 WebCodecs 构建的音视频处理 SDK
- 录制摄像头、麦克风 DEMO (opens new window)
- Web Audio API (opens new window)
- JS 交互增加声音 (opens new window)
- PCM 音量控制 (opens new window)
- AudioData (opens new window) 、 AudioEncoder (opens new window)
- WebAV audioResample 源码 (opens new window)
- WebAV createESDSBox 源码 (opens new window)
- wave-resampler (opens new window) PCM audio resampler written entirely in JavaScript